- A-
- A+
Chiến lược phát triển mô hình ngôn ngữ
Trước đây, để tìm kiếm thông tin và tài liệu cũng như các ý tưởng cho bài viết, tôi thường sử dụng Google. Nhưng từ hai tháng nay, khi công cụ Trí tuệ nhân tạo (AI) ChatGPT của hãng Open AI, mà tỷ phú Elon Musk là đồng sáng lập, ra mắt công chúng, việc dùng cơ chê tìm kiếm (search engine) giảm hẳn.
Hãng này đã đưa ra báo động đỏ (code red) sau khi ChatGPT ra mắt. Microsoft đầu tư 10 tỷ vào hãng khởi nghiệp Open AI, khởi động cuộc chiến công cụ tìm kiếm, do Google thống trị hơn 20 năm nay.
Trí tuệ nhân tạo (AI) hay học máy (machine learning) là khái niệm công nghệ tiên tiến. Nhiều người dùng các dịch vụ do công nghệ này cung cấp hàng ngày. Từ việc xem những khuyến mãi trên trang web của Amazone và các trang chợ điện tử đến việc xem những khuyến nghị các bộ phim trên Netflix, các bài nhạc trên Spotify.
Bạn có thể ra lệnh bằng giọng nói sử dụng Siri trên iPhone, Google Assistant trên điện thoại Android. Nhưng trải nghiệm trực tiếp, hội thoại thú vị với một công cụ AI như ChatGPT chưa từng có trước đây. Và điều này tạo nên cơn sốt với hơn 100 triệu người dùng đăng ký sử dụng hai tháng nay và 13 triệu người dùng hàng ngày.
Sử dụng ChatGPT với các câu hỏi bằng ngôn ngữ tiếng Anh tốt hơn bằng các ngôn ngữ khác. Theo tiến sĩ Thompson của Life AI, ngữ liệu tiếng Anh chiếm đến hơn 92% trong tồng số 570 GB dữ liệu huấn luyện cho mô hình ngôn ngữ lớn (Large Language Model) này.
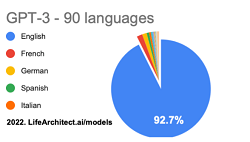
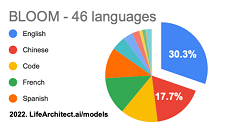
Các ngữ liệu khác chiếm vị trí khá khiêm tốn và điều này khiến cho năng lực xử lý ngôn ngữ khác tiếng Anh khá hạn chế. Các nhà khoa học đã hiểu rõ những hạn chế này, và cộng đồng AI đã thực hiện sáng kiến mã nguồn mở (Open Source) cho mô hình ngôn ngữ lớn với tên gọi Bloom. Mô hình này có 176 tỷ tham số vo với 175 tỷ tham số của mô hình GPT 3.5 mà Open AI dựa vào để xây dựng nên công cụ ChatGPT.
Đây là sự hợp tác sâu rộng với sự tham gia của hơn 1000 nhà nghiên cứu từ hơn 70 quốc gia và hơn 250 tổ chức, dẫn đến kết quả cuối cùng là 117 ngày huấn luyện (train) mô hình Bloom trên siêu máy tính Jean Zay (Paris, Pháp) nhờ khoản tài trợ điện toán trị giá ước tính khoảng 3 triệu € từ các cơ quan nghiên cứu của Pháp CNRS và GENCI. Dù ngữ liệu tiếng Anh vẫn chiếm đa số (trên 30%) nhưng có sự phân bố ngữ liệu ưu tiên hơn cho các ngôn ngữ khác như Trung quốc (17%) và của Châu Âu như Pháp, Tây Ban Nha, Đức, Ý.
Tuy nhiên, với các mô hình ngôn ngữ lớn, vấn đề quan trọng là chi phí huấn luyện, vận hành bên cạnh các khả năng nghiên cứu khoa học. Siêu máy tính được phát triển cho OpenAI (tính đến tháng 5 năm 2020) là một hệ thống duy nhất có hơn 285.000 lõi CPU, 10.000 GPU, sử dụng GPU NVIDIA Tesla V100 được phát hành vào tháng 5/2017, được thay thế bởi GPU NVIDIA Ampère A100 vào tháng 5/2020, và 400 gigabit trên mỗi giây kết nối mạng cho mỗi máy chủ GPU. Xếp hạng Top 5 trong 500 siêu máy tính lớn nhất thế giới và được vận hành trên nền tảng đám mây Azure của Microsoft.
Để huấn luyện mô hình GPT-3 với 175 tỷ tham số sẽ cần khoảng 288 năm với một hệ thống dùng một GPU NVIDIA V100 duy nhất. Giá GPU NVIDIA V100 hay GPU NVIDIA Ampère A100 khoảng 10.000 USD, điều này ngoài tầm với của cá nhân và các doanh nghiệp vừa và nhỏ (SMEs).
Theo một ước tính của tạp chí CIO, OpenAI có thể chi ít nhất 100 nghìn đô la mỗi ngày hoặc 3 triệu đô la hàng tháng cho chi phí vận hành. Để phục vụ một yêu cầu (request) của người dùng trong 13 triệu người dùng thế giới, cần phải có hệ thống gồm 5 GPU A100 và như vậy chỉ có hãng công nghệ hùng mạnh cỡ Microsot mới có thể thực hiện được.
Trở lại vấn đề mô hình ngôn ngữ lớn cho quốc gia, hầu hết các quốc gia nói chung và Việt Nam nói riêng đã xây dựng chiến lược phát triển AI. Tuy nhiên, với tình hình thay đổi nhanh chóng, cần cập nhật ngay chiến lược phát triển mô hình ngôn ngữ lớn, một nhánh đang chiếm vị trí trung tâm trong các hoạt động chiến lược hiện nay.
Việc ứng dụng AI làm tăng hiệu suất công việc lên gấp 4,5 lần và mang lại các giá trị kinh tế xã hội khá lớn. Nhu cầu có một dịch vụ ChatGPT của người Việt, do người Việt làm chủ và phục vụ nhu cầu thiết thực của người Việt là điều hết sức cần thiết.
Chính phủ cần nhanh chóng hành động
Chọn lựa mô hình đầu tư: Chúng ta nên áp dụng những thành quả của nhân loại thay vì phát minh lại từ đầu. Như vậy, có thể sử dụng các LLL sẵn có dưới hai dạng: LLM đóng và mở.
Chúng ta có thể lựa chọn mô hình nguồn mở Bloom hay OPT-175B của Meta, tương đương với ChatGPT cho mô hình quốc gia. Những cải tiến trong LLL bắt đầu với sự giới thiêu công nghệ Transformer (2107) là kết quả của nhiều thập kỷ đổi mới máy học và máy tính cũng như những tiến bộ công nghệ và việc triển khai đòi hỏi:
Phần cứng: Xây dựng kết hợp với cấu trúc GPU cải tiến và song song hóa cho phép huấn luyện các mô hình lớn hơn với lượng dữ liệu lớn hơn (hàng trăm, hàng ngàn hệ thống A100 của Nvidia). Một hệ thống 8GPU bộ nhớ 80GB Ram khoảng 100.000 USD. Đầu tư ban đầu khoảng 100 hệ thống, bằng 1/10 hệ thống của ChatGPT khoảng 10 triệu USD.
Dữ liệu: Đây là vấn đề cơ bản nhất, mặc dù khá tẻ nhạt nhưng lại chiếm đến 80% khối lượng công việc. EleutherAI đã mất 12-18 tháng để thống nhất, thu thập, làm sạch và chuẩn bị dữ liệu cho The Pile, công cụ AI của họ. Lưu ý, nếu The Pile chỉ có ~400 tỷ token so ~1400 tỷ token huấn luyện mô hình Chinchilla. Dù tham số là một yếu tố, xác định kích cỡ của LLL nhưng không phải là tất cả.
Một minh chứng là mô hình Chinchilla, sử dụng cùng một ngân sách điện toán như Gopher nhưng có 70 tỷ tham số và nhiều dữ liệu hơn gấp 4 lần, đã có hiệu năng hơn mô hình Gopher với nhiều tham số (280 tỷ) hơn. Các mô hình ngôn ngữ lớn hiện tại “được huấn luyện dưới mức đáng kể” (significantly undertrained). Đây là hệ quả của việc mở rộng mô hình một cách mù quáng mà không chú trọng đến dữ liệu huấn luyện đầu vào. Làm cho các mô hình lớn hơn, nhiều tham số hơn không phải là cách duy nhất để cải thiện hiệu suất.
Thời gian huấn luyện: Để huấn luyện một mô hình, cần 9-12 tháng huấn luyện và đó là nếu mọi thứ diễn ra hoàn hảo. Có thể cần huấn luyện nhiều lần và huấn luyện song song nhiều mô hình để tối ưu va so sánh.
Học với ít lần huấn luyện (Few shot learning): LLM được hưởng lợi từ việc học ít lần, LLM thể thực hiện một số nhiệm vụ nhất định mà không cần huấn luyện cụ thể. Việc huấn luyện ở tầm quốc gia chỉ tập trung vào các ngữ liệu tổng quát. Những lĩnh vực cụ thể (y tế, giáo dục, luật pháp, nghiên cứu khoa học) sẽ thúc đẩy sự đổi mới và sáng tạo khởi nghiệp, vì việc gắn nhãn các tập dữ liệu (label data) theo truyền thống là một nút cổ chai và chiếm chi phí lớn cho việc huấn luyện.
Nhân sự: Lĩnh vực AI đòi hỏi tài năng về lĩnh vực mũi nhọn này. Tuy nhiên, tôi tin đây lại là thế mạnh của Việt Nam. Chúng ta rất giỏi trong việc nghiên cứu và áp dụng AI. Nhưng cần một cơ chế và điều phối, điều này đang là trở ngại cho những dự án tầm chiến lược quốc gia.
Tóm lại, sự xuất hiện của các mô hình ngôn ngữ lớn, như ChatGPT, đã mang đến một kỷ nguyên mới của công nghệ trí tuệ nhân tạo; và có khả năng cách mạng hóa cách chúng ta tương tác với máy tính và thế giới xung quanh.
Tuy nhiên, sự hạn chế của các ngôn ngữ không phải tiếng Anh và chi phí đào tạo và vận hành các mô hình này cao là một thách thức đáng kể đối với việc áp dụng và sử dụng rộng rãi ở các quốc gia như Việt Nam.
Để giải quyết thách thức này, điều cần thiết là chính phủ và doanh nghiệp lớn phải đầu tư phát triển một mô hình ngôn ngữ lớn phục vụ nhu cầu thiết thực của người Việt Nam. Bằng cách sử dụng các mô hình nguồn mở hiện có như Bloom và OPT-175B, đồng thời đầu tư vào phần cứng và chuẩn bị dữ liệu cần thiết. Việt Nam có thể tận dụng sức mạnh của AI để tăng hiệu quả công việc và mang lại lợi ích kinh tế xã hội to lớn cho người dân.
Với tư cách là nhà tư vấn công nghệ, tôi thực sự khuyến nghị chính phủ và doanh nghiệp cần nhanh chóng hành động để cập nhật các chiến lược phát triển AI và ưu tiên phát triển dịch vụ ChatGPT cho người dân Việt Nam.
Bằng cách đó, chúng ta có thể đảm bảo rằng không ai bị bỏ lại phía sau trong cuộc đua đổi mới công nghệ và người Việt có thể hưởng lợi toàn bộ tiềm năng của công nghệ mới thú vị này.
Theo: https://infonet.vietnamnet.vn/chatgpt-nao-cho-viet-nam-5015309.html